

I was impressed by the consistent quality of work delivered by QUALITANCE, as well as by their flexibility, solid technical understanding, and very useful feedback to our design requirements.
Andrei Agapi, Deutsche Telekom Architect
Context
 At Deutsche Telekom – one of the largest telco operators in the world – handling the configuration, maintenance and monitoring of hundreds of thousands of backbone routers and other network devices is a time-consuming, expensive, and error-prone process. The telco giant asked QUALITANCE to build parts of a scalable automation solution that would allow them to efficiently manage massive amounts of data in a cluster-based setup.
At Deutsche Telekom – one of the largest telco operators in the world – handling the configuration, maintenance and monitoring of hundreds of thousands of backbone routers and other network devices is a time-consuming, expensive, and error-prone process. The telco giant asked QUALITANCE to build parts of a scalable automation solution that would allow them to efficiently manage massive amounts of data in a cluster-based setup.
Challenge
The telco infrastructure was built on Cassandra DB. The old data model and structure could not scale and keep up the pace with Deutsche Telekom’s ever-growing network of devices, e.g. Ethernet switches, 4G & 5G routers, internet routers, residential gateways.
A major milestone was finding a way to expand DT’s system capabilities for data management operations from a single-server, non-scalable implementation to a cluster architecture.

Solution
The implemented solution needed to support reading, writing, updating, and deleting configuration data (network and device parameters) from routers and other network devices, e.g. pertaining routers and other network devices in a scalable and fault-tolerant manner.
We needed to create a high-speed, scalable way to partition and deploy configs, as well as a test harness to validate the correctness of the config operations.
Our solution uses YANG data modeling language to structure data stored in the Cassandra DB backend in YANG-compliant XML, making the data available to Java and Python client libraries. Data is stored and retrieved using Xpath queries, efficiently querying and computing data stored in a distributed database.
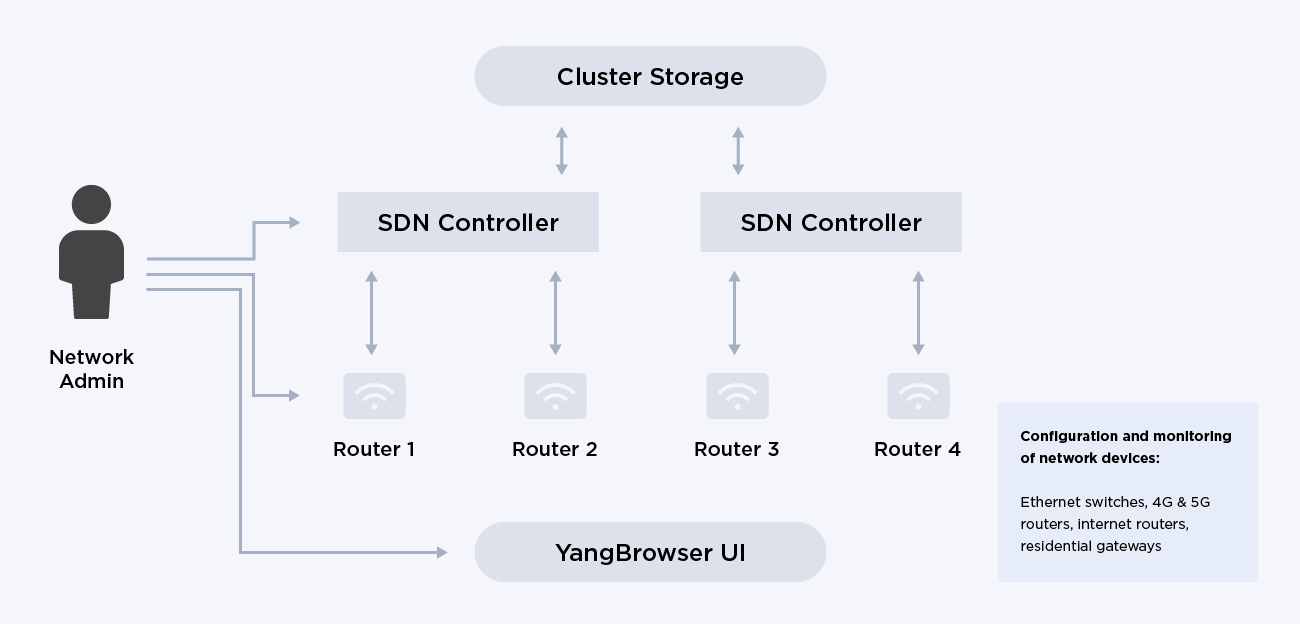
The storage system also dynamically maintains runtime query statistics. Based on this information, data in the backend database is continuously re-partitioned with the help of multi-level graph partitioning algorithms, to achieve optimal performance. Thus, the query patterns facilitate a more efficient data redistribution across the network.
As a result, Xpath queries are solved involving fewer distributed database nodes, and the efficiency in processing data increases considerably.
With this new data system in place, Deutsche Telekom can bolster big data processing automation and scale up the configuration and monitoring of its entire network of devices. The load balancing and replication of data across database clusters eliminate downtime and prevent servers from getting overloaded.
